
인공지능
추상적
사람이 생각하는 것을 본떠 기계에 구현한 것
생각 메커니즘
동기부여 - 강화 - 비교(탐색) - 경험
인간의 추상화 과정을 모델링
길을 찾을 때
Input Layer : 가장 빠른 길은?
Hidden Layers : 막히는 길은 없나?
가까운 길은 없나?
=> 학습
Output Layer : 가장 빠른 길은 여기다.
변수 눈이 온다
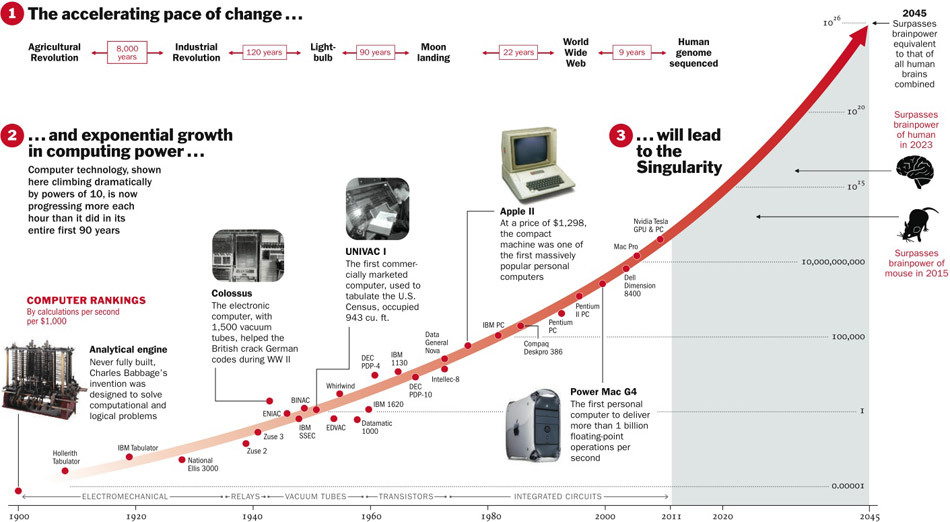
인공지능의 특이점
사람의 지능 네가지
{ 시각 / 소리 / 언어 / 분석 } + 감성(Sentiment)
인공지능이 사람의 지능을 뛰어 넘어도 감성은 불가능(주관적이기 때문)
앞으로 발전하는 지능은 분석 지능
인공지능의 본질은?
인간이 준 정보를 토대로 확률에 기반하여 의사 결정을 하는 시스템의 총칭
인공지능의 시발점, 라이프니츠
= 도서관학의 창시자
현대 인공지능의 출발점
- 심리학 -> 언어지능에 대한 이해 -> 수학(통계학)에 기반한 모델
- 1965년 존 매카시가 다트머스 학회에서 처음 인공지능(Artificial Interlligence)라는 용어를 사용
- LISP 언어를 창시
튜링 테스트
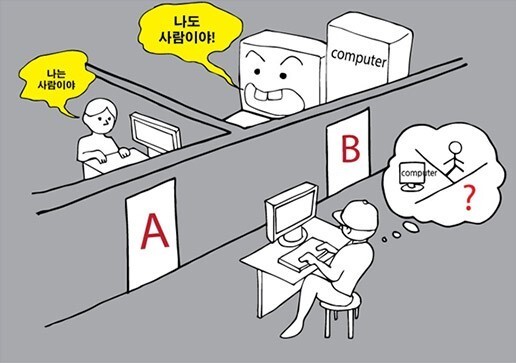
맥락 context
기계와 인간을 차이 짓는 가장 큰 점은 맥락
사전 정보
맥락 정보
기존 데이터를 바탕으로 한 사전 학습으로 강화 필요
기존 데이터엔 고정 데이터가 필수임(ex. 알파벳, 단어처럼 변하지 않는 정보)
기계가 인간의 언어를 이해하기 어려운 이유
1. 사람도 본디 사람 말을 잘 못 알아 듣는다.
2. 기계 번역은 문화적 요인이 많이 들어가서 번역 자체가 어렵다.
ex. 피리부는 사나이의 원제는 하멜른의 쥐잡이
딥러닝 머신러닝
요즘 트렌드는 딥러닝
차이
머신러닝과 딥러닝은 다른 개념
머신러닝 : 인간이 먼저 룰을 정해주고 학습을 돌림(확실한 기준 존재로 인한 한계 존재(융퉁성 없는 결론 도출))
딥러닝 : 먼저 데이터를 수집하고 그 데이터를 바탕으로 기준을 추려서 인간에게 물으면 인간이 알려줌
머신 러닝은 전통적인 인공지능 연구 분야에 보다 가까운 영역(인간의 사고 방식도 머신러닝)
환경에 따른 학습 데이터 필요
자주 쓰이는 용어
- 의사결정나무(Decision Tree)
- SVM(Support Vector Machine)
- K-means 클러스터링
- HMM(Hidden Markov Model)
사용되는 분야
- 지도 학습
- 비지도 학습
- 강화 학습 : 알파고
딥러닝에 자주 쓰이는 용어들
- CNN
- RNN
- LSTM : Long Short Term Memory => 기초학습 후 추가학습 = 오래된 데이터를 백그라운드로 넣어주고 새로운 데이터를 계속 넣어줌
- 인코더
사용 범주
- 범주화(classification)
- 자질(속성) 추출
- 데이터 전처리
- 시계열 기반 데이터 처리
- 객체 인식
- 로봇
최신 기술 트렌드
인공지능 최신 트렌드

Computer vision - ToF 센서 (Time of Flight Sensor) 설명
ai = 확률 = 100%가 존재하지 않음
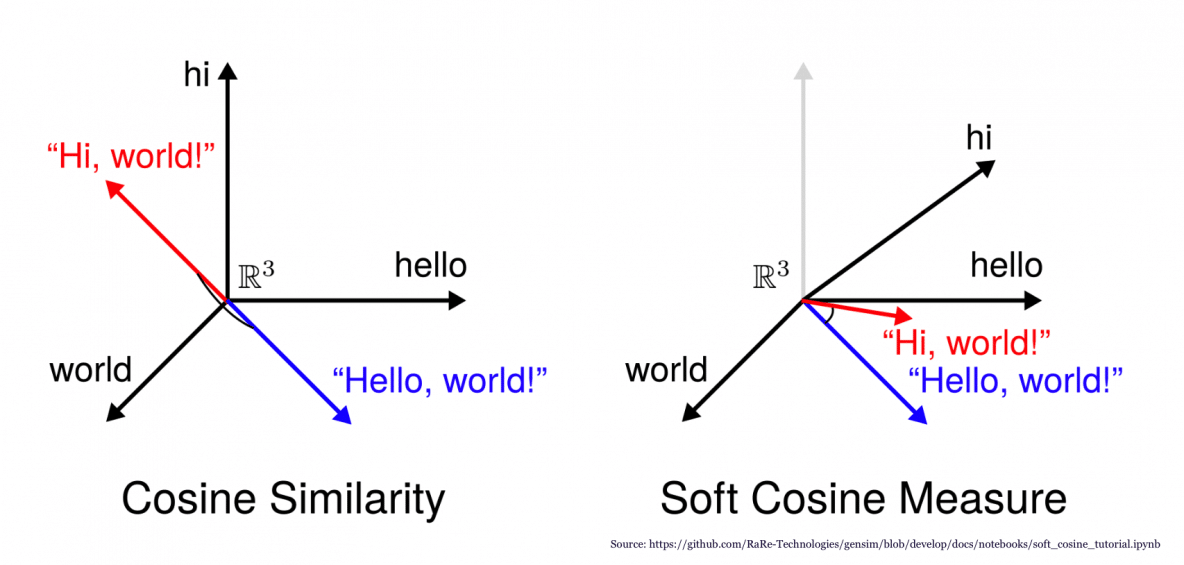
Cosine Measure
인공지능의 기본
구분 지어야 할 개념
검색 : 고르는 것
지능 : 찾아가는 것
@@2Vec
머신러닝의 기본 기술
World2Vec, Doc2Vec...
likeness : ~일 것 같다 를 찾아가는 기술

최신 인공지능 기술들
Transformer : encoding-decoding 제일 많이 사용됨
Elmo
Bert : 질의 응답을 잘해주는 모델

Bart : 기사 요약

기계독해 vs 질의응답
기계독해 : 낮은 수준의 질의 응답(문제하고 답을 모두 넣어줌) / 읽기 지문을 주고, 주관식 질문을 하면 지문에서 답을 찾는 문제
질의응답 : 지문이 없거나 지문의 내용에서 추론해서 답을 만드는 문제
빅데이터와 V
빅데이터
큰 용량, 빠른 속도, 그리고(또는) 높은 다양성을 갖는 정보 자산으로서 이를 통해 의사 결정 및 통찰 발견, 프로세스 최적화를 향상시키기 위해서는 새로운 형태의 처리 방식이 필요하다(Gartner, 2012)
빅데이터는 문제부터 정의 후 데이터 수집이 이루어져야한다.
데이터를 수집할 가치가 있느냐 => 행정의 영역(손해를 따져서...)
과거의 V3
Volume(양)
Variety(다양성)
Velocity(속도) : 매우 중요(시간이 존재해야 과거 데이터 분석, 예측 등이 가능)
새로운 V3
Veracity(정확성)
Variability(가변성)
Visualization(시각화)
제조 빅데이터
데이터 수집 과정 중요!(정상 데이터만 100% 엄청 많이 쌓임 => 분석 불가 / 잘못될 확률을 찾는 게 핵심)
Value : 고객이 원하는 value(전기료 절약, 불량 감소, 제작 단가 낮춤 등)
빅데이터 종류
비정형 데이터
정형 데이터
작은 분석 값
BI
| 전통적 데이터 | 빅데이터(정형/비정형) | |
| 데이터 원천 | 전통적 정보 서비스 | 일정화된 정보 서비스 디바이스, 기기 발생 데이터 |
| 생성 주체 | 업무 관련 담당자(인간) 기업, 정부 등 조직 내 |
SNS 데이터: 개인, 대중 산업데이터: 장비, 기기, 시스템 |
| 목적 | 업무진행 및 효율성 제고 | SNS 데이터: 소통, 표현, 기반 서비스 산업 데이터: 생산관리, 품질극대화 등 |
| 데이터 유형 | 정형 데이터 고객 정보, 거래 정보 비공개 대인 관련 데이터 |
비정형 데이터(영상, 이미지, 텍스트) 장비, 기기 데이터 공개 데이터 |
| 데이터 특징 | 데이터 증가량 관리 가능 신뢰성이 높은 핵심 데이터 위주 |
기하급수적으로 양적 증가 분류 못할 경우 쓰레기 데이터로 분류 문맥, 품질, 트렌드 정보 등 다양 |
| 데이터 보유 | 기업, 정부 등 조직 | 서비스 기업(구글, 아마존) 포털, 온라인 쇼핑몰 이동통신 회사 디바이스 관련 업체 일체 |
정형 데이터 : 엑셀로 정리할 수 있음
데이터에 대한 신뢰도가 굉장히 중요
IoT Device의 폭증
ex. 스마트 홈 => cloud의 경우 해킹에 취약하기 때문에 edge에서 끝나야한다(정상적인 상황에선 집에서만 끝나고 긴급상황에서만 신호가 위로 올라간다던지)
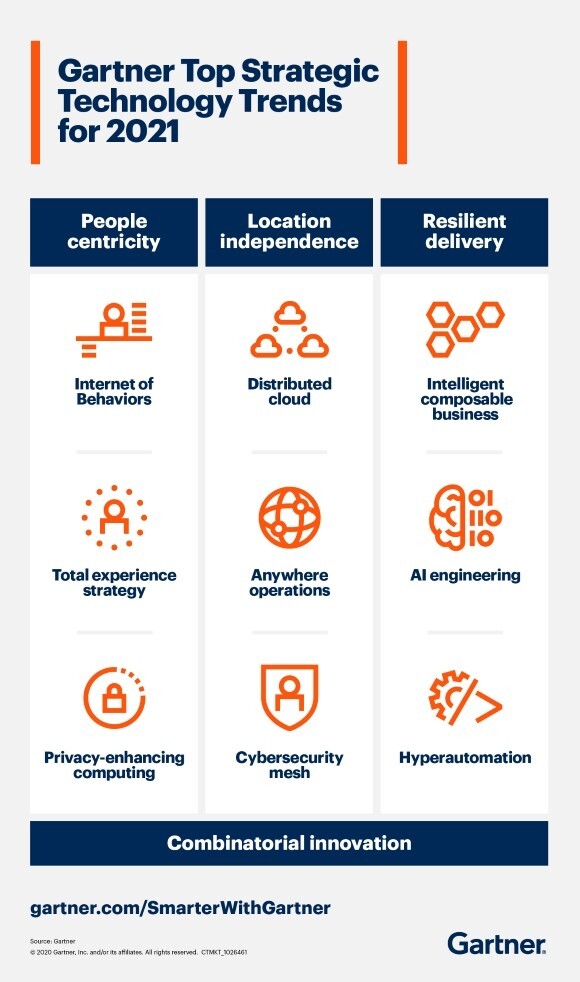
Gartner Top Strategic Technology Trends for 2021
사람 중심성 / 위치 독립성 / 탄력적인 전달
AI 데이터 / 빅데이터 가장 큰 차이
AI 데이터 : 라벨 필요
빅데이터 : 시간 필요
IIoT 데이터의 증가
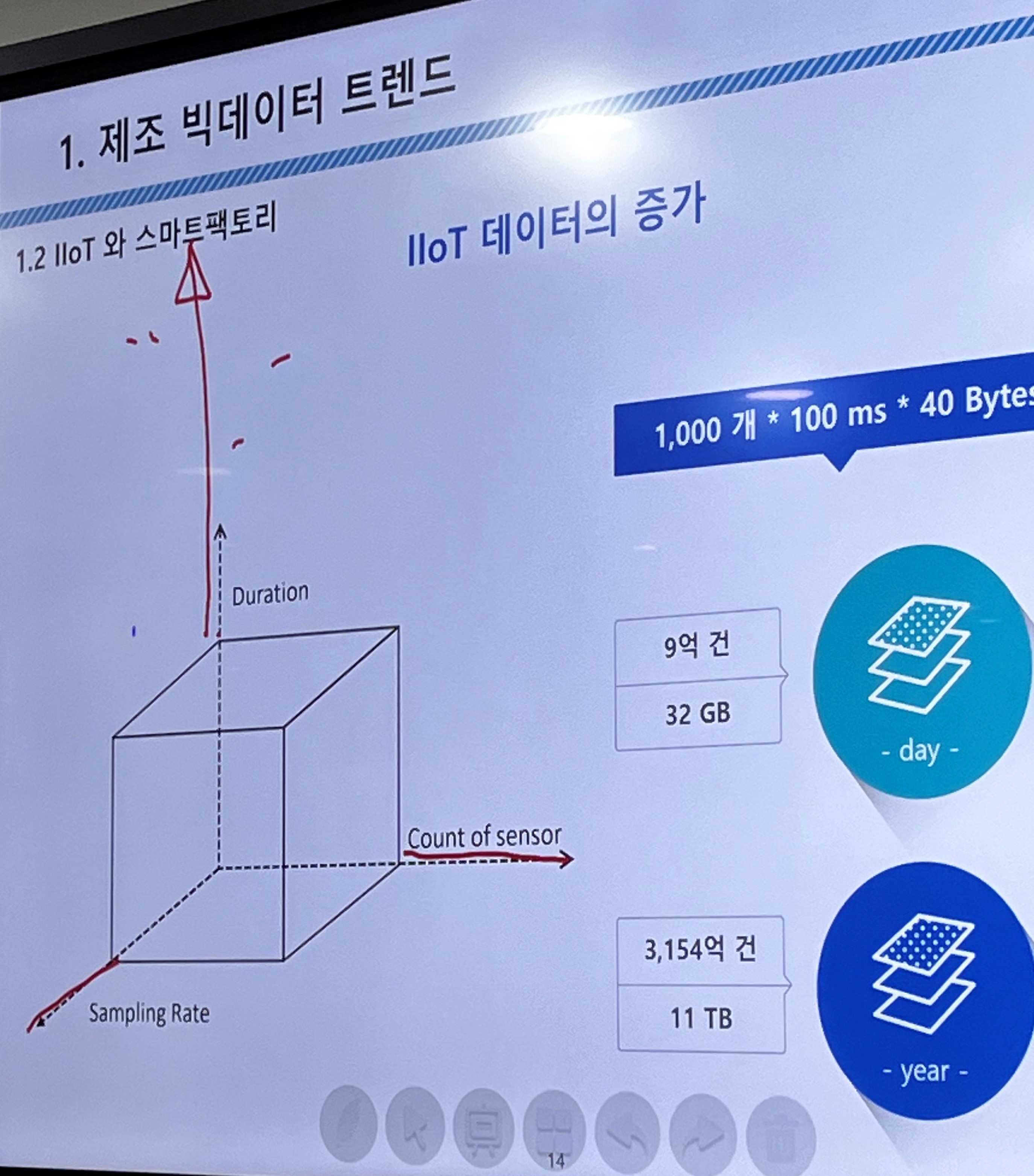
Industrial IoT 데이터 추이
데이터가 점점 더 늘어나 Smart Factory 시대의 데이터 처리 요구량은 현재 처리능력보다 늘어날 수밖에 없음
문제
센서가 과연 타당한 숫자인가?(고객의 cost에도 직결)
Edge Computing Layer for Machine Learning

SCADA

X-SCADA | 국내 최신 기술력이 적용된 스마트팩토리 솔류션
X-SCADA는 Industry 4.0을 위한 최신기술이 집약된 혁신적인 산업자동화 소프트웨어 개발 툴입니다.
www.xisom.com
느낀 점
평소에 생각 안해본 지점들을 많이 생각해 볼 수 있어 좋았다.
얼마나 생각 없이 살았나 반성이 좀 됐다...
인공지능이 사람과 많이 닮아서 신기했다. 당연히 사람이 만들었으니 사람과 닮을 수 밖에 없겠지만!
'공부 > [TIL] Digital Twin Bootcamp' 카테고리의 다른 글
| TIL_220215_환경구축 (1) | 2022.02.15 |
|---|---|
| TIL_220210_IIoT CPS / 클라우드 컴퓨팅 (0) | 2022.02.10 |
| TIL_220209_Git / Docker (1) | 2022.02.09 |
| TIL_220208_DevOps / Docker (0) | 2022.02.08 |
| TIL_220207_DevOps/Git/Github (0) | 2022.02.07 |