
Chapter 6. 메모리와 캐시 메모리
목표
- RAM의 특징과 종류에 대해 학습한다.
- 논리 주소와 물리 주소의 차이를 이해한다.
- 논리 주소를 물리 주소로 변환하는 방법을 이해한다.
- 캐시 메모리와 저장 장치 계층 구조의 개념을 이해한다.
01. RAM의 특징과 종류
1. RAM(메모리)
- 실행할 프로그램의 명령어와 데이터를 저장
- 휘발성 저장 장치 : 전원을 끄면 RAM에 저장된 명령어와 데이터는 모두 날아감 <-> 비휘발성 저장 장치 ex. SSD, 하드 디스크, USB 등
- CPU가 실행하고 싶은 프로그램이 보조 기억장치에 있을 때, RAM으로 복사하여 저장 후, 실행함
- 램의 용량이 크면 많은 프로그램들을 동시에 실행하는 데에 유리. 단, 용량이 필요 이상으로 커지면 속도가 비례하진 않음
2. DRAM Dynamic RAM
- 시간이 지나면 저장한 데이터가 점차 사라지는 RAM
-> 데이터의 소멸을 막기 위해 일정 주기로 데이터를 재활성화(다시 저장)해야 함
- 소비 전력이 비교적 낮고, 저렴하고, 집적도가 높기 때문에 대용량으로 설계하기 유리 -> 일반적으로 메모리로써 많이 사용함
3. SRAM Static RAM
- 시간이 지나도 저장된 데이터가 사라지지 않음
- 일반적으로 DRAM보다 속도가 더 빠름
- 집적도 낮음, 소비 전력 큼, 가격 더 비쌈 -> 캐시 메모리로 사용함(대용량 필요 X)
| DRAM | SRAM | |
| 재충전 | 필요함 | 필요 없음 |
| 속도 | 느림 | 빠름 |
| 가격 | 저렴함 | 비쌈 |
| 집적도 | 높음 | 낮음 |
| 소비 전력 | 적음 | 높음 |
| 사용 용도 | 주기억장치(RAM) | 캐시 메모리 |
4. SDRAM Synchronous Dynamic RAM
- 클럭 신호와 동기화된, 발전된 형태의 DRAM
- 클럭에 맞춰 동작하며, 클럭마다 CPU와 정보를 주고받을 수 있는 DRAM
5. DDR SDRAM Double Data Rate SDRAM
- 최근 가장 흔히 사용되는 RAM
- 대역폭*을 넓혀 전송 속도가 빠른 SDRAM
- DDR4 SDRAM -> DDR SDRAM보다 대역폭이 열여섯배 넓음 -> 최근 흔히 사용
*대역폭 : 데이터를 주고받는 길의 너비
02. 메모리의 주소 공간
1. 물리 주소
- 메모리가 사용
- 정보가 실제로 저장된 하드웨어상의 주소
2. 논리 주소
- CPU, 실행 중인 프로그램이 사용
- 실행 중인 프로그램 각각에게 부여된 0번지부터 시작되는 주소
-> 두 주소는 CPU와 메모리의 상호작용을 위해 서로 간의 변환이 필요함
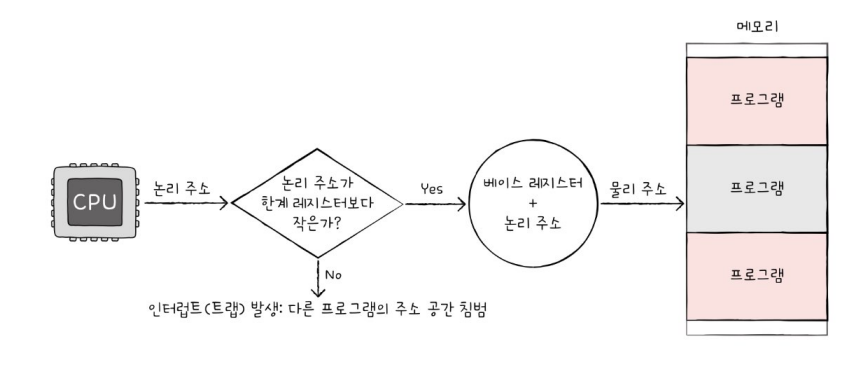
3. 메모리 관리 장치 MMU
- CPU와 주소 버스 사이에 위치
- 논리 주소와 물리 주소 간의 변환 담당 -> CPU가 발생시킨 논리 주소 값 + 베이스 레지스터* 값
*베이스 레지스터 : 프로그램의 가장 작은 물리 주소 = 첫 물리 주소
4. 한계 레지스터 limit register
- 논리 주소 범위를 벗어나는 명령어 실행을 방지, 실행 중인 프로그램이 다른 프로그램에 영향을 받지 않도록 보호하는 역할
- 논리 주소의 최대 크기를 저장
-> 프로그램의 물리 주소 범위 = 베이스 레지스터 값 이상 + 한계 레지스터 값 미만

5. 인터럽트(트랩)
- CPU가 한계 레지스터보다 높은 논리 주소에 접근 시도할 때 발생하여 실행을 중단함
03. 캐시 메모리
1. 저장 장치
- 일반적으로 저장 장치가 따르는 명제
- CPU와 가까울수록 저장 장치의 속도는 빠르다. 반대로 멀수록 저장 장치는 느리다.
- 속도가 빠른 저장 장치일수록 용량이 작고 가격이 비싸다.
- 저장 장치 계층 구조
- CPU에 얼마나 가까운가

2. 캐시 메모리 cash memory
- CPU와 메모리 사이에 위치한 저장 장치로 SRAM 기반
- 레지스터 보다 용량이 크고 메모리보다 빠름
- CPU의 연산 속도와 메모리 접근 속도의 차이를 줄이기 위해 사용
- CPU에서 사용할 데이터를 미리 저장함
3. 캐시 메모리 계층
- 코어와 가까운 순서대로 계층을 구성함
- 가까울 수록 숫자가 작음 -> L1, L2, L3 순
- L1과 L2 캐시는 코어마다 고유한 캐시 메모리로 할당
- L3 캐시는 여러 코어가 하나의 L3를 공유하는 형태로 사용
| 항목 | 비교 |
| 용량 | L1 < L2 < L3 |
| 속도 | L1 > L2 > L3 |
| 가격 | L1 > L2 > L3 |
4. 분리형 캐시(split cache)
- L1 캐시의 접근 속도를 조금이라도 더 빨리 하기 위해 L1 캐시를 분리하는 것을 의미
- L1I 캐시(Level 1 Instruction): 명령어만을 저장하는 캐시
- L1D 캐시(Level 1 Data): 데이터만 저장하는 캐시
5. 참조 지역성 원리
- 캐시 메모리는 CPU가 사용할 법한 대상을 예측해서 저장
- 캐시 히트 cache hit : 자주 사용될 것으로 예측해서 캐시 메모리에 저장한 데이터가 CPU에서 사용된 경우

- 캐시 미스 cache miss : 캐시 메모리에 저장했지만 예측이 틀려 CPU가 메모리에서 필요한 데이터를 가져오는 경우

- 캐시 적중률
- 캐시가 히트되는 비율
- 캐시 히트 횟수 ./ (캐시 히트 횟수 + 캐시 미스 횟수)
6. 참조 지역성의 원리 locality of reference, principle of locality
- CPU가 주로 메모리에 접근하는 경향을 바탕으로 만들어진 원리
- 시간 지역성 : CPU는 최근에 접근한 메모리 공간에 다시 접근하는 경향이 있음
- 공간 지역성 : CPU는 접근한 메모리 공간 근처를 접근하는 경향이 있음
Chapter 7. 보조기억장치
목표
- 하드 디스크 구조와 작동 원리를 이해한다.
- 플래시 메모리 구조와 작동 우너리를 이해한다.
- RAID의 의미와 다양한 RAID 레벨을 학습한다.
01. 하드 디스크
1. 하드 디스크란
- 자기적인 방식으로 데이터를 저장(= 자기 디스크의 일종)
2. 플래터
- 실질적으로 데이터가 저장되는 곳
- 자기 물질로 덮여 있어 수많은 N극, S극을 저장함(0과 1의 역할 수행)
3. 스핀들
- 플래터를 회전 시키는 역할
- RPM : 분당 회전수, 스핀들이 플래터를 돌리는 속도
4. 헤드
- 플래터를 대상으로 데이터를 읽고 쓰는 구성 요소
- 바늘처럼 생김. 플래터 위에 미세하게 떠서 데이터를 읽고 씀
5. 디스크 암
- 헤드를 이동시키는 역할


6. 트랙
- 플래터가 데이터를 저장하는 단위
- 플래터를 여러 동심원으로 나누었을 때, 그 중 하나의 원 ex. 운동장의 달리기 트랙
7. 섹터
- 트랙이 여러 조각으로 나뉘어질 때, 한 조각
- 하드 디스크의 가장 작은 전송 단위
- 일반적으로 512byte, 하지만 하드 디스크에 따라 크기가 달라짐

8. 실린더
- 여러 겹의 플래터 상에서 같은 트랙이 위치한 곳을 모아 연결한 논리적 단위

02. 저장된 데이터에 접근하는 과정
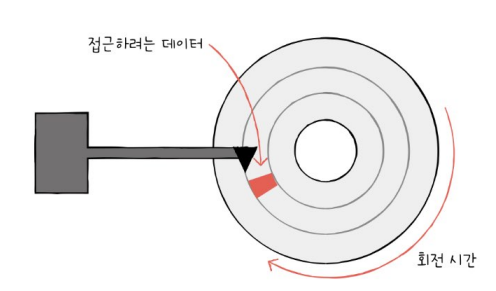
- 탐색 시간 seek time : 데이터가 저장된 트랙까지 헤드를 이동시키는 시간

- 회전 지연 rotational latency : 헤드가 있는 곳으로 플래터를 회전시키는 시간
- 전송 시간 transfer time : 하드 디스크와 컴퓨터 간에 데이터를 전송하는 시간
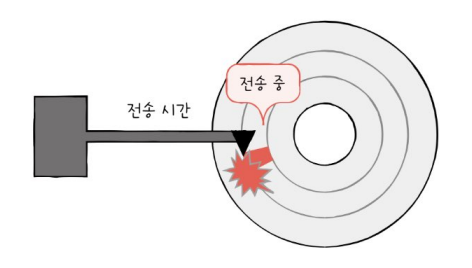
-> 성능에 큰 영향을 끼침
--> 데이터에 접근 시, 플래터 혹은 헤드의 움직임을 최소화하는 것이 중요!
참고 : 하드 디스크 작동 모습
03. 플래시 메모리
1. 플래시 메모리란
- 전기적으로 데이터를 읽고 쓸 수 있는 반도체 기반의 저장 장치 ex. USB 메모리, SD 카드, SSD
- 다양한 곳에서 널리 사용하는 저장 장치
2, 플래시 메모리의 큰 종류
- NAND 플래시 메모리 : NAND 연산을 수행하는 회로를 기반으로 만들어진 메모리
-> 대용량 저장 장치로 많이 사용
-> 이번 내용에서 다룰 메모리
- NOR 플래시 메모리 : NOR 연산을 수행하는 회로를 기반으로 만들어진 메모리
16. 셀 cell
1. 셀이란?
- 플래시 메모리에서 데이터를 저장하는 가장 작은 단위
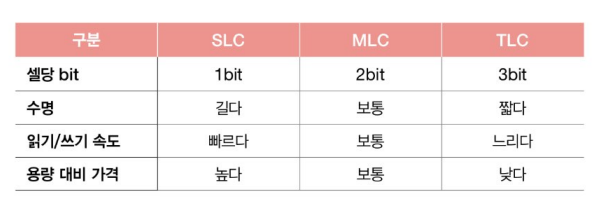
- 하나의 셀에 저장할 수 있느 비트에 따라 플래시 메모리 종류가 나뉨
- SLC single level cell : 한 셀에 1bit 저장
- MLC multiple level cell : 한 셀에 2bit 저장
- TLC triple level cell : 한 셀에 3bit 저장
- QLC quadruple level cell : 한 셀에 4bit 저장(책에선 다루지 않음)
2. 페이지 page
- 셀들이 모여 만들어진 단위
- Free 상태 : 데이터 X, 새로운 데이터 저장 가능한 상태
- Valid 상태 : 이미 유효한 데이터를 저장하고 있는 상태 -> 덮어쓰기 불가능
- Invalid 상태 : 쓰레기값(유효하지 않은 데이터)을 저장하고 있는 상태
3. 블록 block
- 페이지가 모여 만들어진 단위 -> 블록 단위로 삭제가 수행됨
4. 플레인 plane
- 블록이 모여 만들어진 단위
5. 다이 die
- 플레인이 모여 만들어진 단위

6. 가비지 컬렉션 garbage collection
- 유효한 페이지들만 새로운 블럭으로 복사하고, 기존의 블록을 삭제하는 기능
04. RAID의 정의
- Redundant Array of Independent Disks
- 주로 하드 디스크와 SSD를 사용하는 기술
- 데이터의 안전성 혹은 높으 ㄴ성능을 위해 여러 개의 물리적 보조기억장치를 하나의 논리적 보조기억장치처럼 사용하는 기술
05. RAID의 종류
1. RAID 레벨
- RAID를 구성하는 방법
- RAID 0, RAID 1, RAID 2, RAID 3, RAID 4, RAID 5, RAID 6, RAID 10, RAID 50 등
2. RAID 0
- 여러 개의 보조기억장치에 데이터를 단순히 나누어 저장하는 구성 방식 = 하드 디스크 개수 만큼 데이터가 나뉘어 저장됨

- 스트라입 stripe : 줄무늬처럼 분산되어 저장된 데이터
- 스트라이핑 striping : 분산하여 저장하는 방식
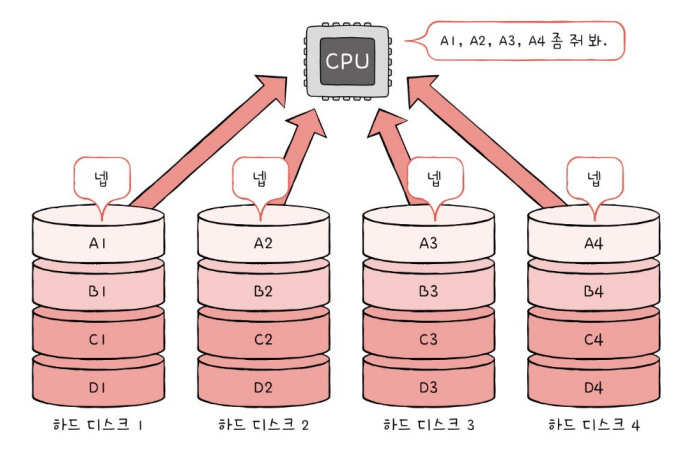
-> 속도가 빠름
- 단점 : 하드 디스크 중 하나에 문제가 생기면 다른 모든 하드 디스크의 정보를 읽을 때 문제가 발생할 수 있어 저장된 정보가 안전하지 않음
3. RAID 1
- 복사본을 만드는 방식
- 미러링 mirroring : 마치 거울처럼 완전한 복사본을 만드는 구성
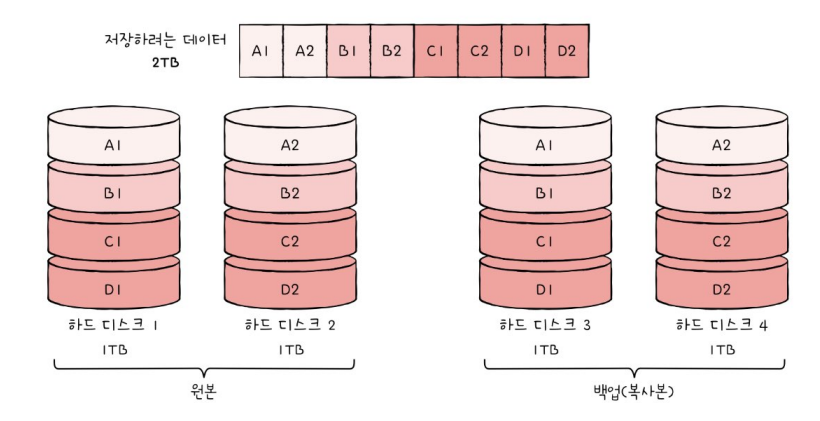
- 원본과 복사본 두 군데에 저장하기 때문에 RAID 0보다 속도는 느리나, 복구가 매우 간단함
- 단점 : 하드 디스크 개수가 한정되면 사용 가능한 용량이 적어짐
4. RAID 4
- 패리티 비트*를 저장한 장치를 두는 구성 방식
* 패리티 비트 parity bit : 오류를 검출하고 복구하기 위한 정보
- 다른 장치들의 오류를 검출, 복구하기 때문에 RAID 1보다 적은 하드 디스크를 요구
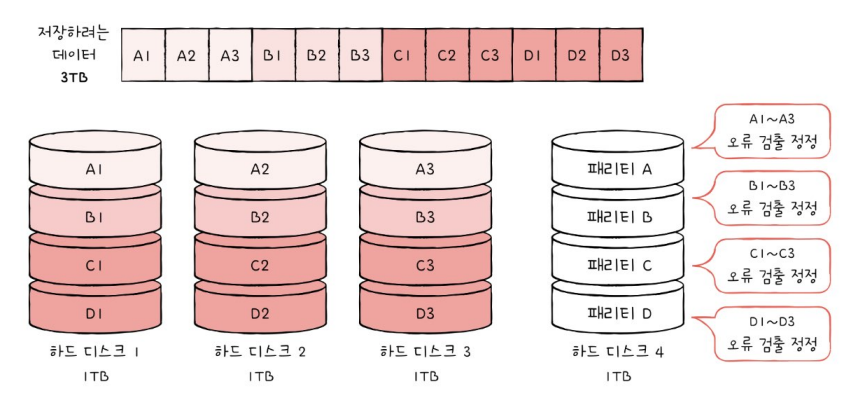
- 단점 : 패리티 저장 장치에 병목 현상이 발생함
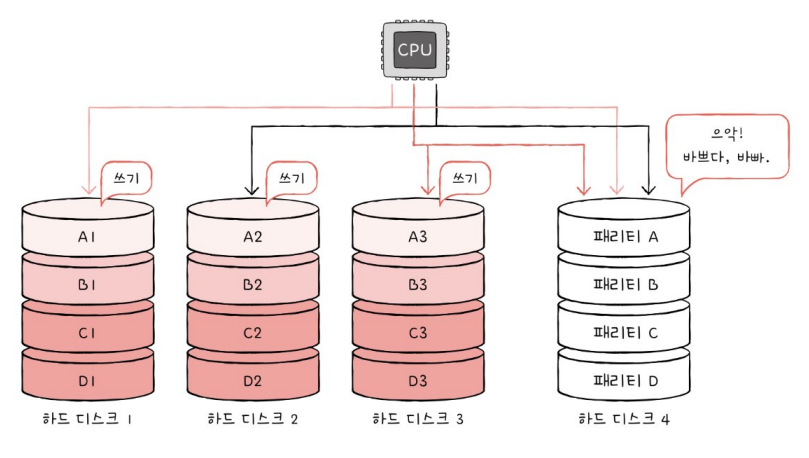
5. RAID 5
- 패리티 정보를 분산하여 저장하는 방식
-> RAID 4의 병목 현상을 해결함

6. RAID 6
- 서로 다른 두 개의 패리티를 두는 방식
- 오류 검출, 복구 수단이 두 개 -> 더욱 안전한 구성
- 단점 : 패리티가 두 개라서 쓰기 속도는 좀 느림

'공부 > TIL' 카테고리의 다른 글
| 한입 크기로 잘라 먹는 타입스크립트 : 타입스크립트 기본 (1) | 2023.08.14 |
|---|---|
| 한입 크기로 잘라 먹는 타입스크립트 : 타입스크립트 개론 (1) | 2023.08.09 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 4 - 5 (0) | 2023.07.30 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 1 - 3 (1) | 2023.07.29 |
| [Nods.js] dgram을 이용한 UDP 채팅 서버 구현 (1) | 2023.07.15 |