
오늘은 수업 전 git hub 클론 코딩을 해보고자 git bash를 설치했다.
저번에 개 안면 인식을 위한 코드를 이용했다.
가상환경 이름은 dogface로 했다.
* 가상환경 만들다가 출력이 멈추면 esc 누르면 됨
객체 검출
Tensorflow Object Detection API의 학습 완료된 모델 그래프(.pb)로 객체 검출
(* pb : protocol buffer : 0과 1로 이루어진 binary 파일과 비슷하다고 생각하면 됨)
라벨 맵 파일을 정규표현식으로 읽어서 객체에 표현
tensorflow란 이름의 가상환경을 만들고
pip install tensorflow명령어를 사용해 tensorflow를 설치했다.(opencv도 설치 완료)
확인

파이참에서도 확인했다.
import tensorflow as tf
print(tf.__version__)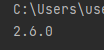
기존에 학습된 모델 사용
COCO 데이터 셋으로 훈련된 모델 사용 링크

new detector.py
import numpy as np
import tensorflow as tf
model = tf.saved_model.load("./ssd_mobilenet_v2_320x320_coco17_tpu-8/saved_model") # saved_model.pb 파일의 상위 경로실행 결과

* path 편하게 붙여넣는 법


실습 : 새 영상 이용
import tensorflow as tf
import numpy as np
import cv2
model = tf.saved_model.load("./ssd_mobilenet_v2_320x320_coco17_tpu-8/saved_model") # saved_model.pb 파일의 상위 경로
capture = cv2.VideoCapture("bird.mp4")
while True:
ret, frame = capture.read()
if capture.get(cv2.CAP_PROP_POS_FRAMES) == capture.get(cv2.CAP_PROP_FRAME_COUNT):
break # 다음 프레임 수가 프레임 총 수와 같아지면 break(영상 재생 다되면 끄겠다)
input_img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 사용된 학습 모델이 RGB 형식이라 RGB로 변경
input_tensor = tf.convert_to_tensor(input_img)# 이미지를 tensor로 변환(tensorflow 기본 단위)
input_tensor = input_tensor[tf.newaxis, ...] # [추론할 이미지 수, 높이, 너비, 채널]
output_dict = model.signatures["serving_default"](input_tensor) # 모델 추론 및 결과 반환 (학습한 320x320 사이즈로)알아서 변환 후 추론
classes = output_dict["detection_classes"][0]# 하나만 쓸거라 0, 여러개 쓸거면 작업을 따로 해야
scores = output_dict["detection_scores"][0] # 얼마나 정확한지 점수(확률)
boxes = output_dict["detection_boxes"][0] # 객체의 좌표(사각형)
height, width, _ = frame.shape
for idx, score in enumerate(scores):
if score > 0.7:
class_id = int(classes[idx])
box = boxes[idx]
x1 = int(box[1] * width)
y1 = int(box[0] * height)
x2 = int(box[3] * width)
y2 = int(box[2] * height)
cv2.rectangle(frame, (x1, y1), (x2, y2), 255, 1)
cv2.putText(frame, str(class_id) + ":" + str(float(score)), (x1, y1 - 5), cv2.FONT_HERSHEY_COMPLEX, 1.5, (0, 255, 255), 1)
cv2.imshow("Object Detection", frame)
if cv2.waitKey(33) == ord("q"):
break
cv2.destroyAllWindows()실행 결과

* 파이참에서 콘솔창 지우기 번거로울 때 clear All 단축키 설정하여 사용하자
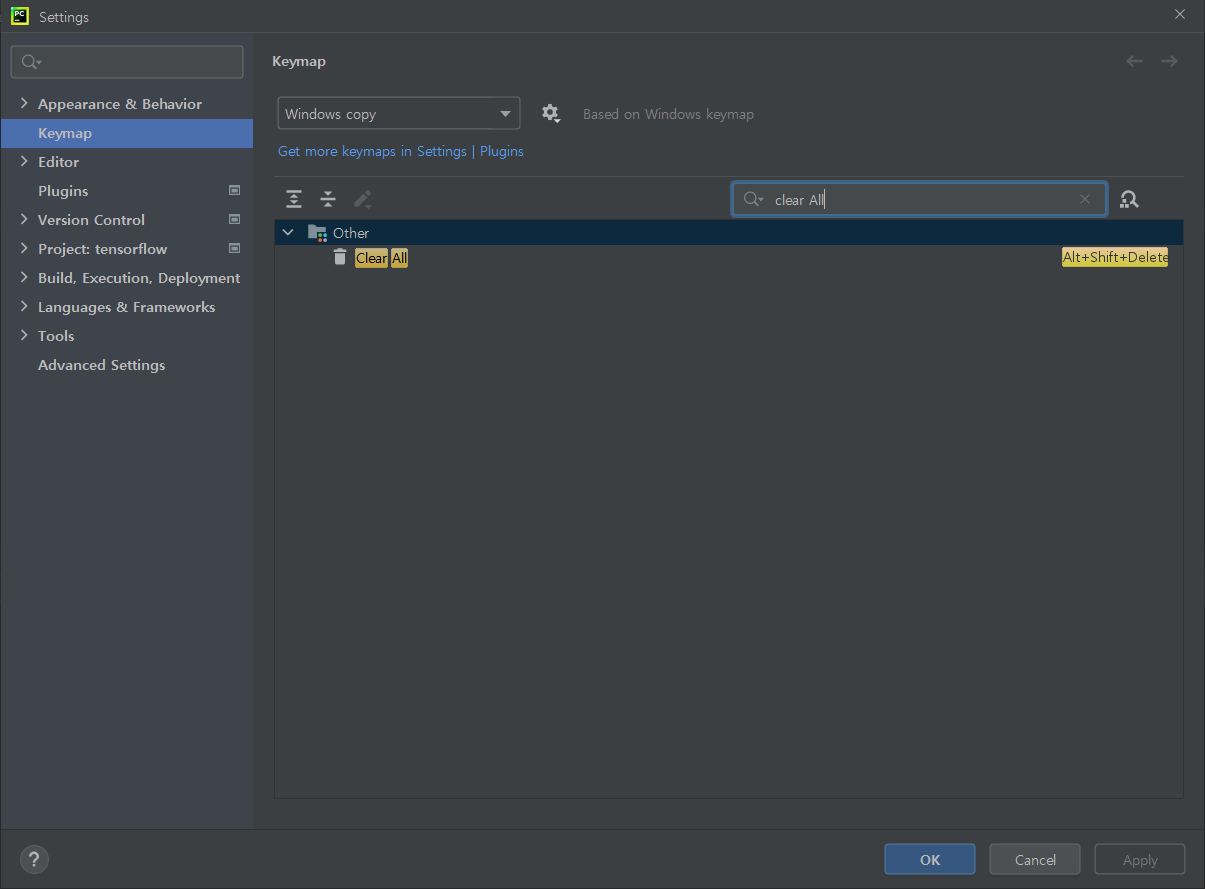
* 파이참에서 기존 콘솔로 사용하기
https://generalbulldog.tistory.com/34
label.py
with open("mscoco_complete_label_map.pbtxt", "rt") as f:
pb_classes = f.read().rstrip("\n").split("\n")
print(len(pb_classes)) # 총 455개 들어있음
print(pb_classes[0]) # item {
print(pb_classes[1]) # name: "background"
print(pb_classes[2]) # id: 0
print(pb_classes[3]) # display_name: "background"
print(pb_classes[4]) # }
'''
결과
455(총 455개)
item {
name: "background"
id: 0
display_name: "background"
}
= iten {\n\n(rstrip으로 \n 하나 지워줌) name: "background"\n id: 0\n display_name: "background"\n }
=> pb 프로토콜로 파일을 읽었음. 근데 pb 프로토콜을 쓰면 item {\n에 \n이 하나 더 붙기 때문에 rstrip으로 하나 지워줌
그리고 split으로 \n을 기준으로 나눠줌
'''빈 dictionary, for문 추가
import re
with open("mscoco_complete_label_map.pbtxt", "rt") as f:
pb_classes = f.read().rstrip("\n").split("\n")
classes_label = dict()
# print(pb_classes) # 위에서 확인했음
for i in range(0, len(pb_classes), 5): # start:0, stop:455, step:5
pb_classId = int(re.findall("\d+", pb_classes[i+2])[0])
# d=정수, +=한자리 이상 => 한자리 수 이상 정수 찾기 pb_classes의 2번째의 첫번째에서 패턴 찾음
# 위에서 한자리수 이상 정수는 id = 0<=
pattern = 'display_name: "(.*?)"'
# ''는 패턴을 표시 | .은 줄바꿈 제외 모든 문자 | *은 0개 이상 | ?는 최소한의 매칭(가장 짧은 문자열을 반환)
# 위에서 display_name: "background" => 패턴이 정확히 일치해야 함
pb_text = re.search(pattern, pb_classes[i+3])
classes_label[pb_classId] = pb_text.group(1)
# group(i)는 찾으려는 패턴에서 ()로 묶여진 명시적 정규식의 i번째 결과 위에서 괄호로 묶여진 첫번쨰는 (.*?)<=
print(pb_text)dictionary 추가(16을 bird로 바꿔주기 위해), 영상 처리(검출 좌표 등) 추가
import tensorflow as tf
import numpy as np
import cv2
import re
model = tf.saved_model.load("./ssd_mobilenet_v2_320x320_coco17_tpu-8/saved_model") # saved_model.pb 파일의 상위 경로
capture = cv2.VideoCapture("bird.mp4")
# 라벨을 위한 dictionary
with open("mscoco_complete_label_map.pbtxt", "rt") as f:
pb_classes = f.read().rstrip("\n").split("\n")
classes_label = dict()
# print(pb_classes) # 위에서 확인했음
for i in range(0, len(pb_classes), 5): # start:0, stop:455, step:5
pb_classId = int(re.findall("\d+", pb_classes[i+2])[0])
# d=정수, +=한자리 이상 => 한자리 수 이상 정수 찾기 pb_classes의 2번째의 첫번째(id=x가 여러개 있을 경우를 대비)에서 패턴 찾음
# 위에서 한자리수 이상 정수는 id = 0<=
pattern = 'display_name: "(.*?)"'
# ''는 패턴을 표시 | .은 줄바꿈 제외 모든 문자 | *은 0개 이상 | ?는 최소한의 매칭(가장 짧은 문자열을 반환)
# 위에서 display_name: "background" => 패턴이 정확히 일치해야 함
pb_text = re.search(pattern, pb_classes[i+3])
classes_label[pb_classId] = pb_text.group(1)
# group(i)는 찾으려는 패턴에서 ()로 묶여진 명시적 정규식의 i번째 결과 위에서 괄호로 묶여진 첫번쨰는 (.*?)<=
while True:
ret, frame = capture.read()
if capture.get(cv2.CAP_PROP_POS_FRAMES) == capture.get(cv2.CAP_PROP_FRAME_COUNT):
break # 다음 프레임 수가 프레임 총 수와 같아지면 break(영상 재생 다되면 끄겠다)
input_img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 사용된 학습 모델이 RGB 형식이라 RGB로 변경
input_tensor = tf.convert_to_tensor(input_img)# 이미지를 tensor로 변환(tensorflow 기본 단위)
input_tensor = input_tensor[tf.newaxis, ...] # [추론할 이미지 수, 높이, 너비, 채널]
output_dict = model.signatures["serving_default"](input_tensor) # 모델 추론 및 결과 반환 (학습한 320x320 사이즈로)알아서 변환 후 추론
classes = output_dict["detection_classes"][0]# 하나만 쓸거라 0, 여러개 쓸거면 작업을 따로 해야
scores = output_dict["detection_scores"][0] # 얼마나 정확한지 점수(확률)
boxes = output_dict["detection_boxes"][0] # 객체의 좌표(사각형)
height, width, _ = frame.shape
for idx, score in enumerate(scores):
if score > 0.7:
class_id = int(classes[idx])
box = boxes[idx]
x1 = int(box[1] * width)
y1 = int(box[0] * height)
x2 = int(box[3] * width)
y2 = int(box[2] * height)
cv2.rectangle(frame, (x1, y1), (x2, y2), 255, 1)
cv2.putText(frame, classes_label[class_id] + ":" + str(float(score)), (x1, y1 - 5), cv2.FONT_HERSHEY_COMPLEX, 1.5, (0, 255, 255), 1)
cv2.imshow("Object Detection", frame)
if cv2.waitKey(33) == ord("q"):
break
cv2.destroyAllWindows()실행 결과

다양한 영상으로 실험



* 주의! 서드 파티 모듈이랑 똑같은 이름의 파일을 만들면 안된다(그 파일이 불러와짐)
느낀 점
말로만 듣던 머신러닝을 직접 이용해보니 정말 신기했다.
앞으로 점점 더 무궁무진하게 발전할 수 있을 것 같다.
'공부 > Digital Twin Bootcamp' 카테고리의 다른 글
| TIL_220106_Backend (0) | 2022.01.06 |
|---|---|
| TIL_210105_Backend (0) | 2022.01.05 |
| TIL_210103_Vision 인식 (0) | 2022.01.03 |
| TIL_211231_Vision 인식 (0) | 2021.12.31 |
| TIL_211230_VISION 인식 (0) | 2021.12.30 |
오늘은 수업 전 git hub 클론 코딩을 해보고자 git bash를 설치했다.
저번에 개 안면 인식을 위한 코드를 이용했다.
가상환경 이름은 dogface로 했다.
* 가상환경 만들다가 출력이 멈추면 esc 누르면 됨
객체 검출
Tensorflow Object Detection API의 학습 완료된 모델 그래프(.pb)로 객체 검출
(* pb : protocol buffer : 0과 1로 이루어진 binary 파일과 비슷하다고 생각하면 됨)
라벨 맵 파일을 정규표현식으로 읽어서 객체에 표현
tensorflow란 이름의 가상환경을 만들고
pip install tensorflow명령어를 사용해 tensorflow를 설치했다.(opencv도 설치 완료)
확인
파이참에서도 확인했다.
import tensorflow as tf
print(tf.__version__)
기존에 학습된 모델 사용
COCO 데이터 셋으로 훈련된 모델 사용 링크
new detector.py
import numpy as np
import tensorflow as tf
model = tf.saved_model.load("./ssd_mobilenet_v2_320x320_coco17_tpu-8/saved_model") # saved_model.pb 파일의 상위 경로실행 결과
* path 편하게 붙여넣는 법
실습 : 새 영상 이용
import tensorflow as tf
import numpy as np
import cv2
model = tf.saved_model.load("./ssd_mobilenet_v2_320x320_coco17_tpu-8/saved_model") # saved_model.pb 파일의 상위 경로
capture = cv2.VideoCapture("bird.mp4")
while True:
ret, frame = capture.read()
if capture.get(cv2.CAP_PROP_POS_FRAMES) == capture.get(cv2.CAP_PROP_FRAME_COUNT):
break # 다음 프레임 수가 프레임 총 수와 같아지면 break(영상 재생 다되면 끄겠다)
input_img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 사용된 학습 모델이 RGB 형식이라 RGB로 변경
input_tensor = tf.convert_to_tensor(input_img)# 이미지를 tensor로 변환(tensorflow 기본 단위)
input_tensor = input_tensor[tf.newaxis, ...] # [추론할 이미지 수, 높이, 너비, 채널]
output_dict = model.signatures["serving_default"](input_tensor) # 모델 추론 및 결과 반환 (학습한 320x320 사이즈로)알아서 변환 후 추론
classes = output_dict["detection_classes"][0]# 하나만 쓸거라 0, 여러개 쓸거면 작업을 따로 해야
scores = output_dict["detection_scores"][0] # 얼마나 정확한지 점수(확률)
boxes = output_dict["detection_boxes"][0] # 객체의 좌표(사각형)
height, width, _ = frame.shape
for idx, score in enumerate(scores):
if score > 0.7:
class_id = int(classes[idx])
box = boxes[idx]
x1 = int(box[1] * width)
y1 = int(box[0] * height)
x2 = int(box[3] * width)
y2 = int(box[2] * height)
cv2.rectangle(frame, (x1, y1), (x2, y2), 255, 1)
cv2.putText(frame, str(class_id) + ":" + str(float(score)), (x1, y1 - 5), cv2.FONT_HERSHEY_COMPLEX, 1.5, (0, 255, 255), 1)
cv2.imshow("Object Detection", frame)
if cv2.waitKey(33) == ord("q"):
break
cv2.destroyAllWindows()실행 결과
* 파이참에서 콘솔창 지우기 번거로울 때 clear All 단축키 설정하여 사용하자
* 파이참에서 기존 콘솔로 사용하기
https://generalbulldog.tistory.com/34
label.py
with open("mscoco_complete_label_map.pbtxt", "rt") as f:
pb_classes = f.read().rstrip("\n").split("\n")
print(len(pb_classes)) # 총 455개 들어있음
print(pb_classes[0]) # item {
print(pb_classes[1]) # name: "background"
print(pb_classes[2]) # id: 0
print(pb_classes[3]) # display_name: "background"
print(pb_classes[4]) # }
'''
결과
455(총 455개)
item {
name: "background"
id: 0
display_name: "background"
}
= iten {\n\n(rstrip으로 \n 하나 지워줌) name: "background"\n id: 0\n display_name: "background"\n }
=> pb 프로토콜로 파일을 읽었음. 근데 pb 프로토콜을 쓰면 item {\n에 \n이 하나 더 붙기 때문에 rstrip으로 하나 지워줌
그리고 split으로 \n을 기준으로 나눠줌
'''빈 dictionary, for문 추가
import re
with open("mscoco_complete_label_map.pbtxt", "rt") as f:
pb_classes = f.read().rstrip("\n").split("\n")
classes_label = dict()
# print(pb_classes) # 위에서 확인했음
for i in range(0, len(pb_classes), 5): # start:0, stop:455, step:5
pb_classId = int(re.findall("\d+", pb_classes[i+2])[0])
# d=정수, +=한자리 이상 => 한자리 수 이상 정수 찾기 pb_classes의 2번째의 첫번째에서 패턴 찾음
# 위에서 한자리수 이상 정수는 id = 0<=
pattern = 'display_name: "(.*?)"'
# ''는 패턴을 표시 | .은 줄바꿈 제외 모든 문자 | *은 0개 이상 | ?는 최소한의 매칭(가장 짧은 문자열을 반환)
# 위에서 display_name: "background" => 패턴이 정확히 일치해야 함
pb_text = re.search(pattern, pb_classes[i+3])
classes_label[pb_classId] = pb_text.group(1)
# group(i)는 찾으려는 패턴에서 ()로 묶여진 명시적 정규식의 i번째 결과 위에서 괄호로 묶여진 첫번쨰는 (.*?)<=
print(pb_text)dictionary 추가(16을 bird로 바꿔주기 위해), 영상 처리(검출 좌표 등) 추가
import tensorflow as tf
import numpy as np
import cv2
import re
model = tf.saved_model.load("./ssd_mobilenet_v2_320x320_coco17_tpu-8/saved_model") # saved_model.pb 파일의 상위 경로
capture = cv2.VideoCapture("bird.mp4")
# 라벨을 위한 dictionary
with open("mscoco_complete_label_map.pbtxt", "rt") as f:
pb_classes = f.read().rstrip("\n").split("\n")
classes_label = dict()
# print(pb_classes) # 위에서 확인했음
for i in range(0, len(pb_classes), 5): # start:0, stop:455, step:5
pb_classId = int(re.findall("\d+", pb_classes[i+2])[0])
# d=정수, +=한자리 이상 => 한자리 수 이상 정수 찾기 pb_classes의 2번째의 첫번째(id=x가 여러개 있을 경우를 대비)에서 패턴 찾음
# 위에서 한자리수 이상 정수는 id = 0<=
pattern = 'display_name: "(.*?)"'
# ''는 패턴을 표시 | .은 줄바꿈 제외 모든 문자 | *은 0개 이상 | ?는 최소한의 매칭(가장 짧은 문자열을 반환)
# 위에서 display_name: "background" => 패턴이 정확히 일치해야 함
pb_text = re.search(pattern, pb_classes[i+3])
classes_label[pb_classId] = pb_text.group(1)
# group(i)는 찾으려는 패턴에서 ()로 묶여진 명시적 정규식의 i번째 결과 위에서 괄호로 묶여진 첫번쨰는 (.*?)<=
while True:
ret, frame = capture.read()
if capture.get(cv2.CAP_PROP_POS_FRAMES) == capture.get(cv2.CAP_PROP_FRAME_COUNT):
break # 다음 프레임 수가 프레임 총 수와 같아지면 break(영상 재생 다되면 끄겠다)
input_img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 사용된 학습 모델이 RGB 형식이라 RGB로 변경
input_tensor = tf.convert_to_tensor(input_img)# 이미지를 tensor로 변환(tensorflow 기본 단위)
input_tensor = input_tensor[tf.newaxis, ...] # [추론할 이미지 수, 높이, 너비, 채널]
output_dict = model.signatures["serving_default"](input_tensor) # 모델 추론 및 결과 반환 (학습한 320x320 사이즈로)알아서 변환 후 추론
classes = output_dict["detection_classes"][0]# 하나만 쓸거라 0, 여러개 쓸거면 작업을 따로 해야
scores = output_dict["detection_scores"][0] # 얼마나 정확한지 점수(확률)
boxes = output_dict["detection_boxes"][0] # 객체의 좌표(사각형)
height, width, _ = frame.shape
for idx, score in enumerate(scores):
if score > 0.7:
class_id = int(classes[idx])
box = boxes[idx]
x1 = int(box[1] * width)
y1 = int(box[0] * height)
x2 = int(box[3] * width)
y2 = int(box[2] * height)
cv2.rectangle(frame, (x1, y1), (x2, y2), 255, 1)
cv2.putText(frame, classes_label[class_id] + ":" + str(float(score)), (x1, y1 - 5), cv2.FONT_HERSHEY_COMPLEX, 1.5, (0, 255, 255), 1)
cv2.imshow("Object Detection", frame)
if cv2.waitKey(33) == ord("q"):
break
cv2.destroyAllWindows()실행 결과
다양한 영상으로 실험
* 주의! 서드 파티 모듈이랑 똑같은 이름의 파일을 만들면 안된다(그 파일이 불러와짐)
느낀 점
말로만 듣던 머신러닝을 직접 이용해보니 정말 신기했다.
앞으로 점점 더 무궁무진하게 발전할 수 있을 것 같다.
'공부 > Digital Twin Bootcamp' 카테고리의 다른 글
| TIL_220106_Backend (0) | 2022.01.06 |
|---|---|
| TIL_210105_Backend (0) | 2022.01.05 |
| TIL_210103_Vision 인식 (0) | 2022.01.03 |
| TIL_211231_Vision 인식 (0) | 2021.12.31 |
| TIL_211230_VISION 인식 (0) | 2021.12.30 |